正则表达式位置匹配——匹配两个特殊符号中间的内容
需求
对于下面的一串字符,需要匹配{}中间的内容
user = {name: "Jack", age: 18}
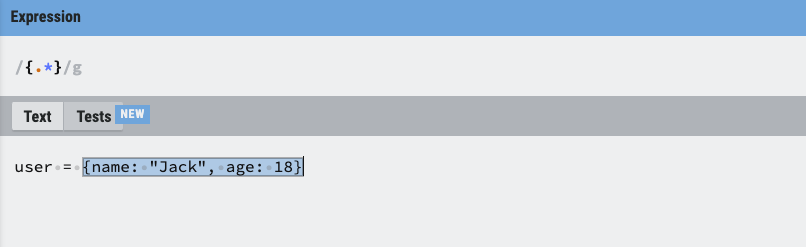
case 1:匹配 {} 中间的内容,并且包含 {} 本身
{.*}
解析:
{匹配{本身.匹配任何字符,除了\n换行符*匹配前面的子表达式 0 次或多次}匹配}本身
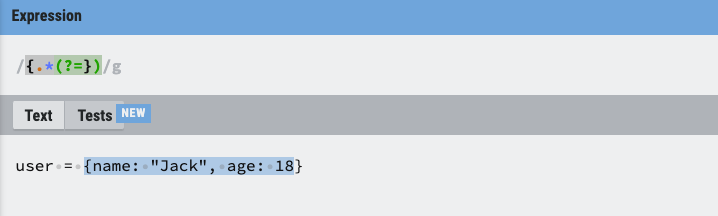
case 2:匹配 {} 中间的内容,包含 { 但不包含 }
{.*(?=})
解析:
前面的跟上面一样,} 变成了 (?=})。这里用到了一个(?=p)的语法,其中 p 是一个子模式,即 p前面的位置。
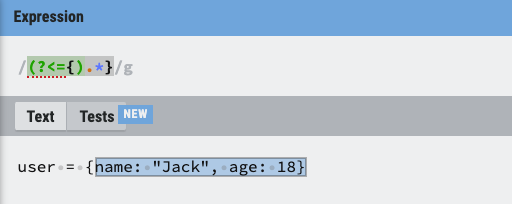
case 3:匹配 {} 中间的内容,包含 } 但不包含 {
(?<={).*}
解析:
跟上一种情况相反。后面的 } 不变,前面的 { 变成了 (?<={)。这里用到了一个 (?<=p) 的语法,其中 p 是一个子模式,即 p 后面的位置。
case 4:匹配 {} 中间的内容,不包含 {} 本身
(?<={).*(?=})

解析:
结合上面两种情况,就可以得出这样的正则表达式。
升级的需求
上面的需求,我们发现是一行语句,如果是多行的匹配呢?同样是匹配 {} 中间的内容,现在变成了多行。
__GetZoneResult_ = {
mts:'1872917',
province:'陕西',
catName:'中国移动',
telString:'18729172911',
areaVid:'30503',
ispVid:'3236139',
carrier:'陕西移动'
}
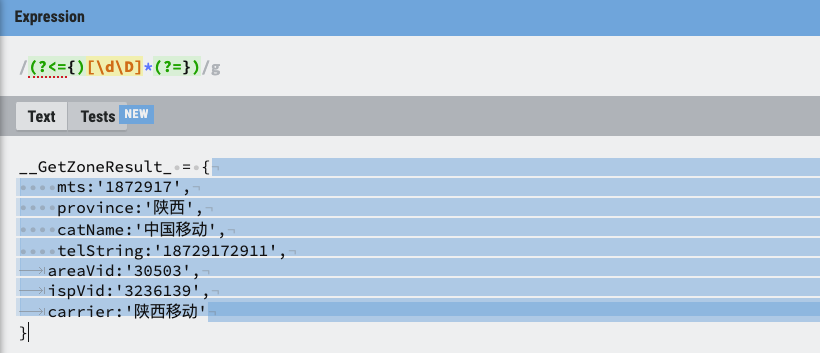
前面的 .* 是匹配除了\n以外的任意字符0次或多次。我们需要改成匹配任意字符0次或多次即可,所以不能用 . 了。
那么,在正则表达式中使用什么可以匹配到所有字符呢?我们可以使用几种元字符的组合。比如:\d 是匹配一个数字字符,\D 是匹配一个非数字字符。那么 [\d\D] 的组合就可以匹配所有字符了。同样的还有以下的组合:
[\w\W][\s\S]
使用位置匹配
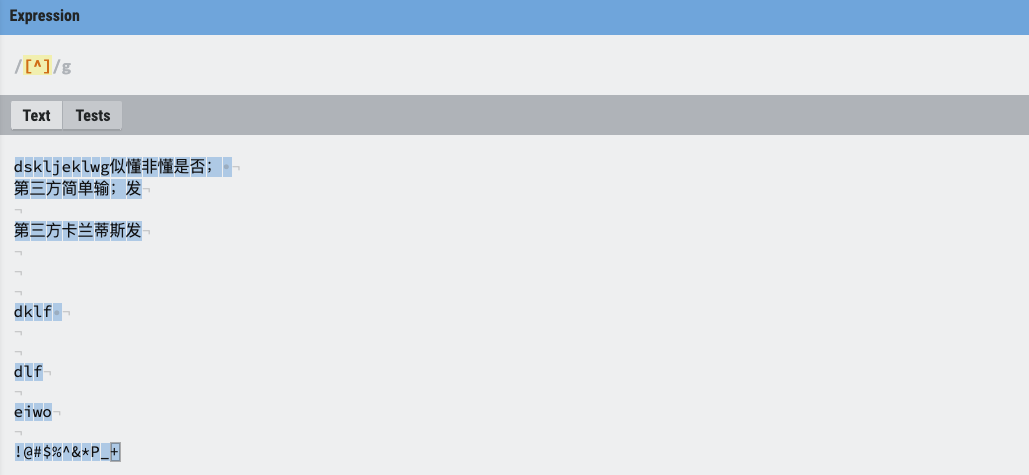
对于上面的需求,我们使用位置匹配也可以达到这样的要求。我们需要借助 ^ 的特性。


[^] 是一个比较神奇的操作,因为 [] 里没有字符集合,不接受没有字符集合那就是所有了。我们可以试验一下,随便写一串字符,用 [^] 可以匹配到所有。
参考: