Q:互斥锁的使用场景是什么?
说起并发访问问题,真是太常见了,比如:
- 多个 goroutine 并发更新同一个资源,像计数器;
- 同时更新用户的账户信息;
- 秒杀系统;
- 往同一个 buffer 中并发写入数据等等。
如果没有互斥控制,就会出现一些异常情况,比如计数器的计数不准确、用户的账户可能出现透支、秒杀系统出现超卖、buffer 中的数据混乱,等等,后果都很严重。这些问题怎么解决呢?对,用互斥锁,那在 Go 语言里,就是 Mutex。
Mutex 前置知识了解
互斥锁是一种常用的控制共享资源访问的方法,它能够保证同时只有一个 goroutine 可以访问共享资源。在学习它的具体实现原理前,我们要先搞懂一个概念,就是临界区。
临界区
在并发编程中,如果程序中的一部分会被并发访问或修改,那么,为了避免并发访问导致的意想不到的结果,这部分程序需要被保护起来,这部分被保护起来的程序,就叫做临界区。
可以说,临界区就是一个被共享的资源,或者说是一个整体的一组共享资源,比如对数据库的访问、对某一个共享数据结构的操作、对一个 I/O 设备的使用、对一个连接池中的连接的调用,等等。
如果很多线程同步访问临界区,就会造成访问或操作错误,这当然不是我们希望看到的结果。所以,我们可以使用互斥锁,限定临界区只能同时由一个线程持有。
当临界区由一个线程持有的时候,其它线程如果想进入这个临界区,就会返回失败,或者是等待。直到持有的线程退出临界区,这些等待线程中的某一个才有机会接着持有这个临界区。
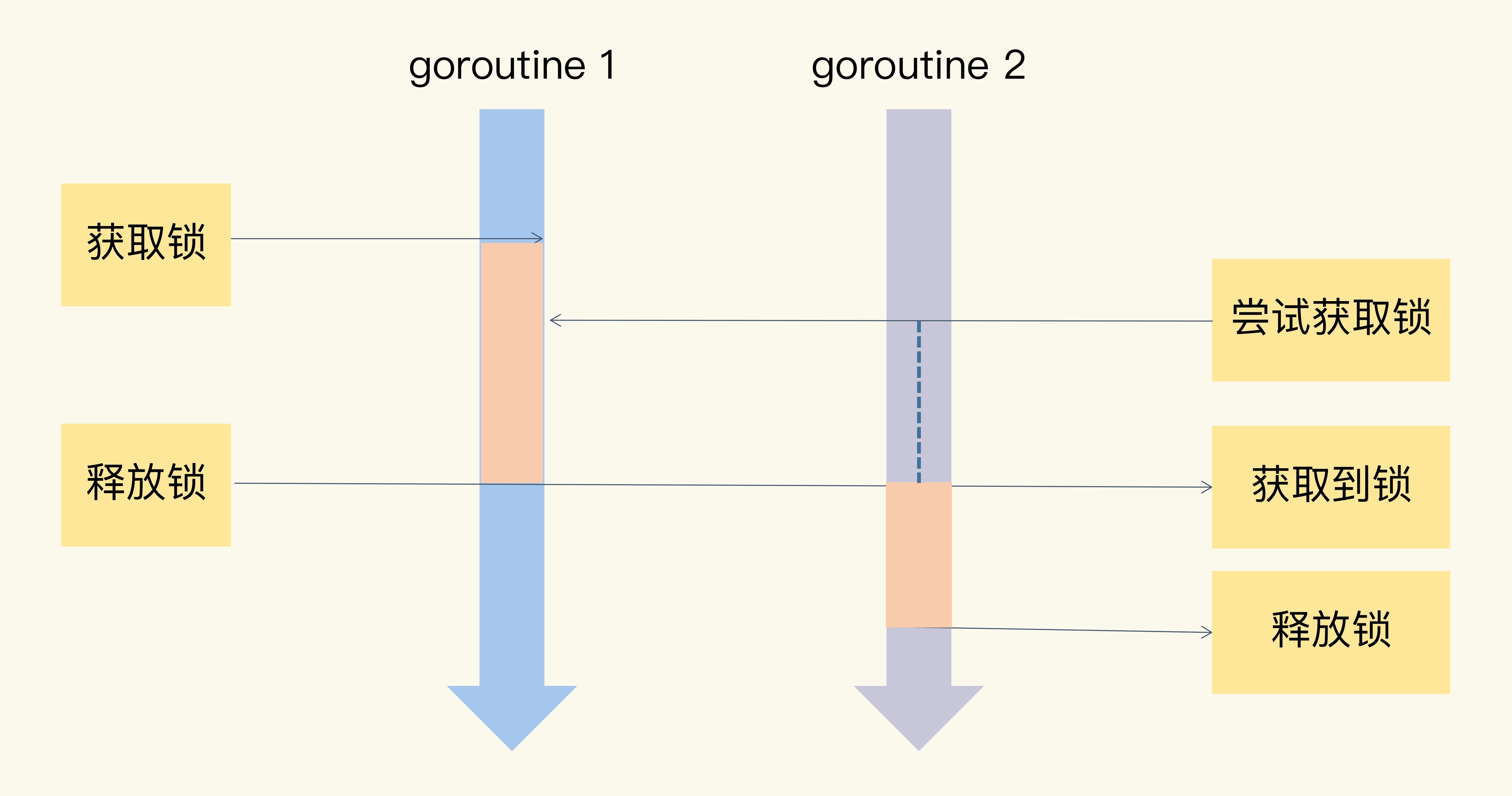
你看,互斥锁就很好地解决了资源竞争问题,有人也把互斥锁叫做排它锁。那在 Go 标准库中,它提供了 Mutex 来实现互斥锁这个功能。
根据 2019 年第一篇全面分析 Go 并发 Bug 的论文Understanding Real-World Concurrency Bugs in Go,Mutex 是使用最广泛的同步原语(Synchronization primitives,有人也叫做并发原语)
sync.Locker 接口
在 Go 的标准库中,package sync 提供了锁相关的一系列同步原语,这个 package 还定义了一个 Locker 的接口,Mutex 就实现了这个接口。
Locker 的接口定义了锁同步原语的方法集:
type Locker interface {
Lock()
Unlock()
}
可以看到,Go 定义的锁接口的方法集很简单,就是请求锁(Lock)和释放锁(Unlock)这两个方法,秉承了 Go 语言一贯的简洁风格。
但是,这个接口在实际项目应用得不多,因为我们一般会直接使用具体的同步原语,而不是通过接口。
Mutex/RWMutex 都实现了 Locker 接口。
Mutex(互斥锁)
基本使用方法
简单来说,互斥锁 Mutex 就提供两个方法 Lock 和 Unlock:进入临界区之前调用 Lock 方法,退出临界区的时候调用 Unlock 方法:
func(m *Mutex)Lock()
func(m *Mutex)Unlock()
// 1.18新增的
func (*Mutex) TryLock()
当一个 goroutine 通过调用 Lock 方法获得了这个锁的拥有权后, 其它请求锁的 goroutine 就会阻塞在 Lock 方法的调用上,直到锁被释放并且自己获取到了这个锁的拥有权。
使用互斥锁能够保证同一时间有且只有一个 goroutine 进入临界区,其他的 goroutine 则在等待锁;当互斥锁释放后,等待的 goroutine 才可以获取锁进入临界区,多个 goroutine 同时等待一个锁时,唤醒的策略是随机的。
sync.Mutex 的零值是一个有效的互斥锁,因此不需要显式初始化它。为了提高性能,我们希望尽量减少持有锁所花费的时间。
跟 mysql 的事务一样,一个事务的时间尽可能短
与许多其他语言不同,Go 互斥锁是非递归的(可以递归的锁叫可重入锁)。如果同一个 goroutine 尝试 Lock() 两次互斥锁,第二个 Lock() 将永远阻塞。
下面是一个使用 Mutex 的例子。在这个例子中,x++操作是非原子操作,需要加锁。x++内部指令如下:
// count++操作的汇编代码
MOVQ "".count(SB), AX
LEAQ 1(AX), CX
MOVQ CX, "".count(SB)
var x int64
var wg sync.WaitGroup
var lock sync.Mutex
func add() {
for i := 0; i < 5000; i++ {
lock.Lock() // 加锁
// x++操作是非原子操作,需要加锁
x++
lock.Unlock() // 解锁
}
wg.Done()
}
func main() {
wg.Add(2)
go add()
go add()
wg.Wait()
fmt.Println(x) // 10000
}
TryLock
1.18 版本新增了一个 TryLock函数,就是尝试获取排它锁。
这个方法具体是什么意思呢?我来解释一下这里的逻辑。当一个 goroutine 调用这个 TryLock 方法请求锁的时候,如果这把锁没有被其他 goroutine 所持有,那么,这个 goroutine 就持有了这把锁,并返回 true;如果这把锁已经被其他 goroutine 所持有,或者是正在准备交给某个被唤醒的 goroutine,那么,这个请求锁的 goroutine 就直接返回 false,不会阻塞在方法调用上。
它与Lock的区别:
Lock 是阻塞的,如果锁已经被其他 goroutine 获取,则调用该方法的 goroutine 会被阻塞直到锁可用。TryLock 方法是一个非阻塞的尝试获取锁的方法,它会立即返回一个布尔值,指示是否成功获取锁。如果成功获取锁,返回 true,否则返回 false。
如下图所示,如果 Mutex 已经被一个 goroutine 持有,调用 Lock 的 goroutine 阻塞排队等待,调用 TryLock 的 goroutine 直接得到一个 false 返回。
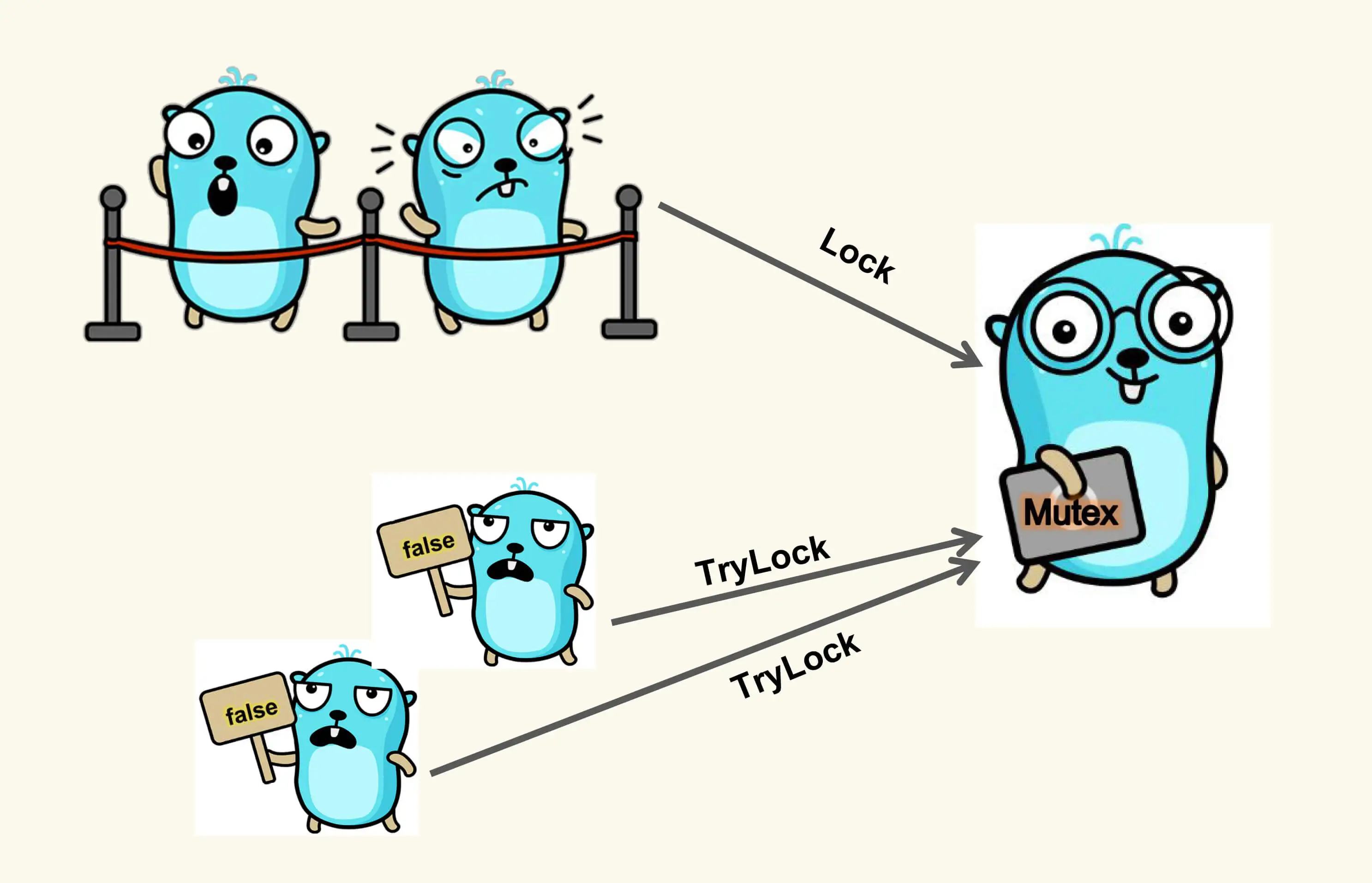
在实际开发中,如果要更新配置数据,我们通常需要加锁,这样可以避免同时有多个 goroutine 并发修改数据。有的时候,我们也会使用 TryLock。这样一来,当某个 goroutine 想要更改配置数据时,如果发现已经有 goroutine 在更改了,其他的 goroutine 调用 TryLock,返回了 false,这个 goroutine 就会放弃更改。
var mu sync.Mutex
func main() {
// 启动一个goroutine持有一段时间的锁
go func() {
mu.Lock()
time.Sleep(time.Duration(rand.Intn(4)) * time.Second)
mu.Unlock()
}()
time.Sleep(time.Second)
// 尝试获取到锁
ok := mu.TryLock()
// 获取成功
if ok {
fmt.Println("got the lock")
// do sth...
mu.Unlock()
return
}
// 没有获取到
fmt.Println("can't get the lock")
}
使用技巧
1. 可以使用 map 将结果缓存下来
package main
import (
"fmt"
"sync"
"time"
)
var cache map[int]int
var mu sync.Mutex
func expensiveOperation(n int) int {
// in real code this operation would be very expensive
time.Sleep(1 * time.Second)
return n
}
func getCached(n int) int {
mu.Lock()
v, isCached := cache[n]
mu.Unlock()
if isCached {
return v
}
v = expensiveOperation(n)
mu.Lock()
cache[n] = v
mu.Unlock()
return v
}
func accessCache() {
total := 0
for i := 0; i < 5; i++ {
n := getCached(i)
total += n
}
fmt.Printf("total: %d\n", total)
}
func main() {
cache = make(map[int]int)
go accessCache()
accessCache()
}
2. 将 mutex 嵌入其他 struct 中使用。通过嵌入字段,你可以在这个 struct 上直接调用 Lock/Unlock方法。
type Counter struct {
sync.Mutex
Count uint64
}
func main() {
var counter Counter
var wg sync.WaitGroup
wg.Add(10)
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
for j := 0; j < 100000; j++ {
counter.Lock()
counter.Count++
counter.Unlock()
}
}()
}
wg.Wait()
fmt.Println(counter.Count)
}
上面map缓存的例子,我们可以这样修改:
type Memo struct {
cache map[int]int
mu sync.Mutex
}
func NewMemo() *Memo {
return &Memo{
cache: make(map[int]int),
}
}
func (m *Memo) Get(key int, f func(int) int, arg int) int {
m.mu.Lock()
// 如果结果已经被缓存,直接返回缓存的值
v, ok := m.cache[key]
m.mu.Unlock()
if ok {
return v
}
// 否则,计算结果并缓存
v = f(arg)
m.mu.Lock()
m.cache[key] = v
m.mu.Unlock()
return v
}
func accessCache() {
memo := NewMemo()
expensiveOperation := func(n int) int {
time.Sleep(1 * time.Millisecond)
return n
}
total := 0
for i := 0; i < 10; i++ {
n := memo.Get(i, expensiveOperation, i)
total += n
}
fmt.Printf("total: %d\n", total)
}
func main() {
go accessCache()
time.Sleep(1 * time.Second)
accessCache()
}
3. 把获取锁、释放锁、计数加一的逻辑封装成一个方法,对外不需要暴露锁等逻辑:
func main() {
// 封装好的计数器
var counter Counter
var wg sync.WaitGroup
wg.Add(10)
// 启动10个goroutine
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
// 执行10万次累加
for j := 0; j < 100000; j++ {
counter.Incr() // 受到锁保护的方法
}
}()
}
wg.Wait()
fmt.Println(counter.Count())
}
// 线程安全的计数器类型
type Counter struct {
CounterType int
Name string
mu sync.Mutex
count uint64
}
// 加1的方法,内部使用互斥锁保护
func (c *Counter) Incr() {
c.mu.Lock()
c.count++
c.mu.Unlock()
}
// 得到计数器的值,也需要锁保护
func (c *Counter) Count() uint64 {
c.mu.Lock()
defer c.mu.Unlock()
return c.count
}
Q:Mutex 的陷阱有哪些?
使用 Mutex 常见的错误场景有 4 类,分别是 Lock/Unlock 不是成对出现、Copy 已使用的 Mutex、重入和死锁。下面我们一一来看。
1. Lock/Unlock 不是成对出现
Lock/Unlock 没有成对出现,就意味着会出现死锁的情况,或者是因为 Unlock 一个未加锁的 Mutex 而导致 panic。
我们先来看看缺少 Unlock 的场景,常见的有三种情况:
- 代码中有太多的 if-else 分支,可能在某个分支中漏写了 Unlock;
- 在重构的时候把 Unlock 给删除了;
- Unlock 误写成了 Lock。
在这种情况下,锁被获取之后,就不会被释放了,这也就意味着,其它的 goroutine 永远都没机会获取到锁。
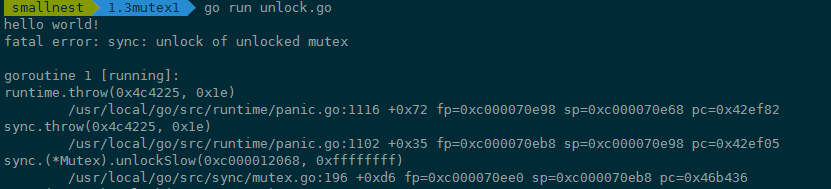
我们再来看缺少 Lock 的场景,这就很简单了,一般来说就是误操作删除了 Lock。 比如先前使用 Mutex 都是正常的,结果后来其他人重构代码的时候,由于对代码不熟悉,或者由于开发者的马虎,把 Lock 调用给删除了,或者注释掉了。比如下面的代码,mu.Lock() 一行代码被删除了,直接 Unlock 一个未加锁的 Mutex 会 panic:
func foo() {
var mu sync.Mutex
defer mu.Unlock()
fmt.Println("hello world!")
}
运行的时候 panic:
2. 不要复制sync.Mutex
sync.Mutex变量的副本以与原始互斥锁相同的状态开始,但它们不是同一个互斥锁。复制 sync.Mutex 几乎总是一个错误,例如:通过将其传递给另一个函数或将其嵌入到结构中并制作该结构的副本。
为什么不能复制 Mutex?原因在于,Mutex 是一个有状态的对象,它的 state 字段记录这个锁的状态。如果你要复制一个已经加锁的 Mutex 给一个新的变量,那么新的刚初始化的变量居然被加锁了,这显然不符合你的期望,因为你期望的是一个零值的 Mutex。关键是在并发环境下,你根本不知道要复制的 Mutex 状态是什么,因为要复制的 Mutex 是由其它 goroutine 并发访问的,状态可能总是在变化。
如果要共享互斥变量,请将其作为指针(*sync.Mutex)传递。
type Counter struct {
sync.Mutex
Count int
}
func main() {
var c Counter
c.Lock()
defer c.Unlock()
c.Count++
foo(c) // 复制锁
}
// 这里Counter的参数是通过复制的方式传入的
func foo(c Counter) {
c.Lock()
defer c.Unlock()
fmt.Println("in foo")
}
3. Mutex 是非递归的
在某些语言中,Mutex 是递归的(可重入锁),即同一个线程可以多次 Lock 同一个 mutex。
可重入锁
当一个线程获取锁时,如果没有其它线程拥有这个锁,那么,这个线程就成功获取到这个锁。之后,如果其它线程再请求这个锁,就会处于阻塞等待的状态。但是,如果拥有这把锁的线程再请求这把锁的话,不会阻塞,而是成功返回,所以叫可重入锁(有时候也叫做递归锁)。只要你拥有这把锁,你可以可着劲儿地调用,比如通过递归实现一些算法,调用者不会阻塞或者死锁。
Mutex 不是可重入的锁。
在 Go 中 sync.Mutex是非递归的。在同一个 goroutine 中 Lock 两次会 deadlock(死锁)。
4. 死锁(deadlock)
两个或两个以上的进程(或线程,goroutine)在执行过程中,因争夺共享资源而处于一种互相等待的状态,如果没有外部干涉,它们都将无法推进下去,此时,我们称系统处于死锁状态或系统产生了死锁。
我们来分析一下死锁产生的必要条件。如果你想避免死锁,只要破坏这四个条件中的一个或者几个,就可以了。
-
互斥: 至少一个资源是被排他性独享的,其他线程必须处于等待状态,直到资源被释放。
-
持有和等待:goroutine 持有一个资源,并且还在请求其它 goroutine 持有的资源,也就是咱们常说的“吃着碗里,看着锅里”的意思。
-
不可剥夺:资源只能由持有它的 goroutine 来释放。
-
环路等待:一般来说,存在一组等待进程,P={P1,P2,…,PN},P1 等待 P2 持有的资源,P2 等待 P3 持有的资源,依此类推,最后是 PN 等待 P1 持有的资源,这就形成了一个环路等待的死结。
你看,死锁问题还真是挺有意思的,所以有很多人研究这个事儿。一个经典的死锁问题就是哲学家就餐问题。
package main
import (
"fmt"
"sync"
"time"
)
func main() {
// 派出所证明
var psCertificate sync.Mutex
// 物业证明
var propertyCertificate sync.Mutex
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done() // 派出所处理完成
psCertificate.Lock()
defer psCertificate.Unlock()
// 检查材料
time.Sleep(5 * time.Second)
// 请求物业证明
propertyCertificate.Lock()
defer propertyCertificate.Unlock()
}()
go func() {
defer wg.Done() // 物业处理完成
propertyCertificate.Lock()
defer propertyCertificate.Unlock()
// 检查材料
time.Sleep(5 * time.Second)
// 请求派出所证明
psCertificate.Lock()
defer psCertificate.Unlock()
}()
wg.Wait()
fmt.Println("成功完成")
}
你可以引入一个第三方的锁,大家都依赖这个锁进行业务处理,比如现在政府推行的一站式政务服务中心。或者是解决持有等待问题,物业不需要看到派出所的证明才给开物业证明,等等。
Q:如何检测死锁?
Go 在运行时,有死锁的检查机制(checkdead() 方法),它能够发现死锁的 goroutine。你肯定不想运行的时候才发现这个因为复制 Mutex 导致的死锁问题,那么你怎么能够及时发现问题呢?可以使用 vet 工具,把检查写在 Makefile 文件中,在持续集成的时候跑一跑,这样可以及时发现问题,及时修复。我们可以使用 go vet 检查这个 Go 文件:
// 希望检查的代码包的路径
go vet path/to/your/package
// 检查一个具体的文件
go vet main.go
// 检查结果
./main.go:18:6: call of foo copies lock value: go-learning.Counter
./main.go:21:12: foo passes lock by value: go-learning.Counter
Q:如何实现可重入锁?
思路:实现的锁要能记住当前是哪个 goroutine 持有这个锁。我来提供两个方案。
-
方案一:通过 hacker 的方式获取到 goroutine id,记录下获取锁的 goroutine id,它可以实现 Locker 接口。
-
方案二:调用 Lock/Unlock 方法时,由 goroutine 提供一个 token,用来标识它自己,而不是我们通过 hacker 的方式获取到 goroutine id,但是,这样一来,就不满足 Locker 接口了。
可重入锁(递归锁)解决了代码重入或者递归调用带来的死锁问题,同时它也带来了另一个好处,就是我们可以要求,只有持有锁的 goroutine 才能 unlock 这个锁。这也很容易实现,因为在上面这两个方案中,都已经记录了是哪一个 goroutine 持有这个锁。
下面我们具体来看这两个方案怎么实现。
方案一:goroutine id
这个方案的关键第一步是获取 goroutine id,方式有两种,分别是简单方式和 hacker 方式。
简单方式,就是通过 runtime.Stack 方法获取栈帧信息,栈帧信息里包含 goroutine id。
func GoID() int {
var buf [64]byte
n := runtime.Stack(buf[:], false)
// 得到id字符串
idField := strings.Fields(strings.TrimPrefix(string(buf[:n]), "goroutine "))[0]
id, err := strconv.Atoi(idField)
if err != nil {
panic(fmt.Sprintf("cannot get goroutine id: %v", err))
}
return id
}
hacker 方式:首先,我们获取运行时的 g 指针,反解出对应的 g 的结构。每个运行的 goroutine 结构的 g 指针保存在当前 goroutine 的一个叫做 TLS 对象中。
第一步:我们先获取到 TLS 对象;
第二步:再从 TLS 中获取 goroutine 结构的 g 指针;
第三步:再从 g 指针中取出 goroutine id。
使用 petermattis/goid 库可以直接获取
go get -u https://github.com/petermattis/goid
// 实现自定义的 RecursiveMutex 结构体
type RecursiveMutex struct {
sync.Mutex
owner int64 // 当前持有锁的 goroutine id
recursion int32 // 这个goroutine 重入的次数
}
func (m *RecursiveMutex) Lock() {
gid := goid.Get()
// 如果当前持有锁的goroutine就是这次调用的goroutine,说明是重入
if atomic.LoadInt64(&m.owner) == gid {
m.recursion++
return
}
m.Mutex.Lock()
// 获得锁的goroutine第一次调用,记录下它的goroutine id,调用次数加1
atomic.StoreInt64(&m.owner, gid)
m.recursion = 1
}
func (m *RecursiveMutex) Unlock() {
gid := goid.Get()
// 非持有锁的goroutine尝试释放锁,错误的使用
if atomic.LoadInt64(&m.owner) != gid {
panic(fmt.Sprintf("wrong the owner(%d): %d!", m.owner, gid))
}
// 调用次数减1
m.recursion--
// 如果这个goroutine还没有完全释放,则直接返回
if m.recursion != 0 {
return
}
// 此goroutine最后一次调用,需要释放锁
atomic.StoreInt64(&m.owner, -1)
m.Mutex.Unlock()
}
import (
"fmt"
"sync"
"sync/atomic"
"github.com/petermattis/goid"
)
var mu RecursiveMutex
func main() {
var foo func()
var bar func()
foo = func() {
fmt.Println("in foo")
mu.Lock()
bar()
mu.Unlock()
}
bar = func() {
mu.Lock()
fmt.Println("in bar")
mu.Unlock()
}
foo()
}
方案二:token
方案一是用 goroutine id 做 goroutine 的标识,我们也可以让 goroutine 自己来提供标识。不管怎么说,Go 开发者不期望你利用 goroutine id 做一些不确定的东西,所以,他们没有暴露获取 goroutine id 的方法。
下面的代码是第二种方案。调用者自己提供一个 token,获取锁的时候把这个 token 传入,释放锁的时候也需要把这个 token 传入。通过用户传入的 token 替换方案一中 goroutine id,其它逻辑和方案一一致。
type TokenRecursiveMutex struct {
sync.Mutex
token int64
recursion int32
}
func (m *TokenRecursiveMutex) Lock(token int64) {
//如果传入的token和持有锁的token一致,说明是递归调用
if atomic.LoadInt64(&m.token) == token {
m.recursion++
return
}
m.Mutex.Lock()
// 抢到锁之后记录这个token
atomic.StoreInt64(&m.token, token)
m.recursion = 1
}
func (m *TokenRecursiveMutex) Unlock(token int64) {
// 释放其它token持有的锁
if atomic.LoadInt64(&m.token) != token {
panic(fmt.Sprintf("wrong the owner(%d): %d!", m.token, token))
}
m.recursion--
// 还没有回退到最初的递归调用
if m.recursion != 0 {
return
}
atomic.StoreInt64(&m.token, 0) // 没有递归调用了,释放锁
m.Mutex.Unlock()
}
// 使用的时候,不同的goroutine应该传入不同的token
var tokenMu TokenRecursiveMutex
var wg sync.WaitGroup
var x int64
func main() {
wg.Add(2)
// token 不同,互不影响
go add(1000)
go add(2000)
wg.Wait()
fmt.Println(x) // 10000
}
func add(token int64) {
defer wg.Done()
for i := 0; i < 5000; i++ {
tokenMu.Lock(token)
x = x + 1
tokenMu.Unlock(token)
}
}
Q:如何使用 Mutex 实现一个线程安全的队列?
var mu sync.Mutex
type Queue struct {
data []any
mu sync.Mutex
}
func NewQueue(n int) *Queue {
return &Queue{data: make([]any, 0, n)}
}
func (q *Queue) Enqueue(v any) {
q.mu.Lock()
q.data = append(q.data, v)
q.mu.Unlock()
}
func (q *Queue) Dequeue() any {
q.mu.Lock()
if len(q.data) == 0 {
q.mu.Unlock()
return nil
}
v := q.data[0]
q.data = q.data[1:]
q.mu.Unlock()
return v
}
思考:
Q:如果 Mutex 已经被一个 goroutine 获取了锁,其它等待中的 goroutine 们只能一直等待。那么,等这个锁释放后,等待中的 goroutine 中哪一个会优先获取 Mutex 呢?
在 Go 中,sync.Mutex 的锁是不保证公平性的,也就是说,并不能保证等待中的 goroutine 会按照它们等待的顺序获得锁。Go 的 Mutex 实现是非公平的,它允许新的 goroutine 插队并在老的 goroutine 之前获取锁。
具体来说,等待中的 goroutine 们在锁被释放后,会由调度器按照某种策略选择一个来获取锁,而这个策略并不是先进先出(FIFO)。这种非公平的锁实现可以减小竞争的开销,并提高整体的性能。
在实际应用中,应该避免依赖于等待 goroutine 的获取顺序,因为这样的顺序是不可预测的。如果有特定的需求,可能需要使用更为复杂的同步机制,比如基于条件变量(sync.Cond)的实现,来实现更精细的控制。但要注意,复杂的同步机制可能带来额外的复杂性和潜在的错误,应慎重使用。
总结
Go 死锁探测工具只能探测整个程序是否因为死锁而冻结了,不能检测出一组 goroutine 死锁导致的某一块业务冻结的情况。你还可以通过 Go 运行时自带的死锁检测工具,或者是第三方的工具(比如 go-deadlock、go-tools)进行检查,这样可以尽早发现一些死锁的问题。不过,有些时候,死锁在某些特定情况下才会被触发,所以,如果你的测试或者短时间的运行没问题,不代表程序一定不会有死锁问题。
并发程序最难跟踪调试的就是很难重现,因为并发问题不是按照我们指定的顺序执行的,由于计算机调度的问题和事件触发的时机不同,死锁的 Bug 可能会在极端的情况下出现。通过搜索日志、查看日志,我们能够知道程序有异常了,比如某个流程一直没有结束。这个时候,可以通过 Go pprof 工具分析,它提供了一个 block profiler 监控阻塞的 goroutine。除此之外,我们还可以查看全部的 goroutine 的堆栈信息,通过它,你可以查看阻塞的 groutine 究竟阻塞在哪一行哪一个对象上了。
与许多其他语言不同,Go 互斥锁是非递归的。如果同一个 goroutine 尝试 Lock() 两次互斥锁,第二个 Lock() 将永远阻塞。